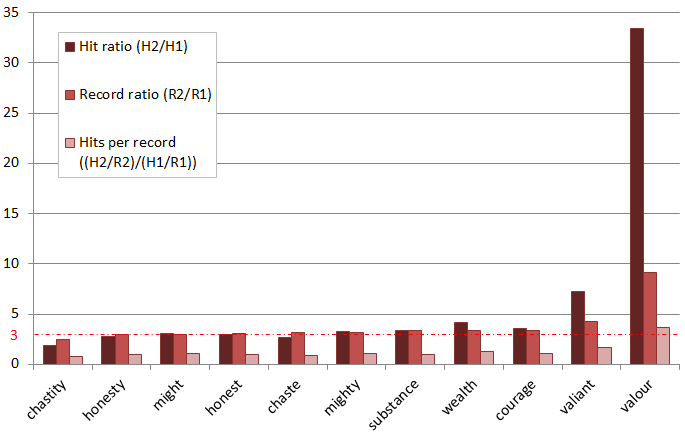
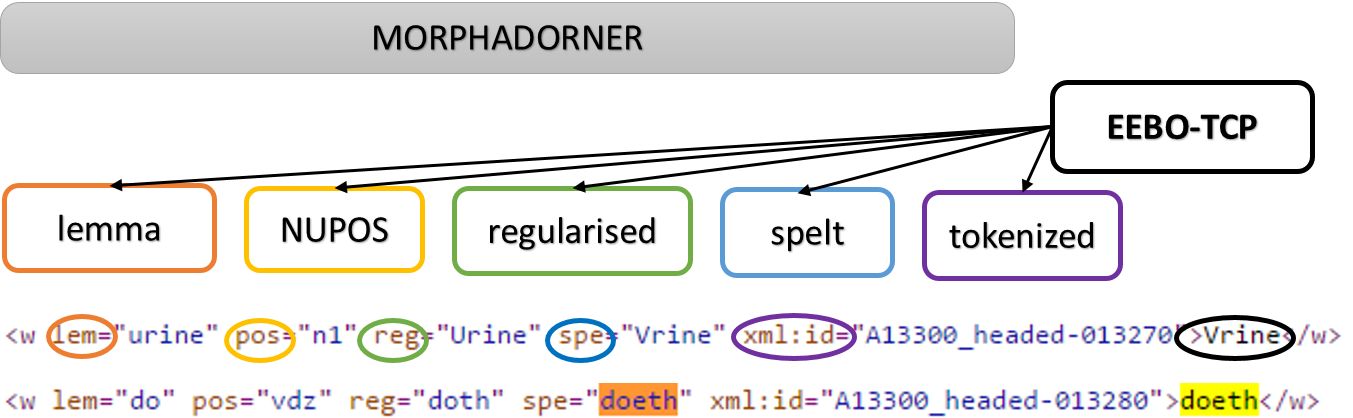
Among the collections provided by Linguistic DNA is one called SuperScience, a broad set of early modern science-writing originally gathered together by Dr Alan Hogarth of the Visualizing English Print project. Here he outlines some other ways to explore those texts.
In September 2017, LDNA researcher Iona Hine presented some work with TCP metadata at DRHA’s dataAche conference. In this guest post, DRHA co-panellist Alan Hogarth (pictured) examines the fruits of his own labour with EEBO-TCP. Alan was responsible for assembling sub-collections of scientific writings as part of the Visualizing English Print group in Strathclyde.
Alan writes:
Using EEBO-TCP’s metadata to search for early modern scientific texts can be a complex activity. The TCP Terms Listings include references from the extremely broad (e.g. ‘Science – Early Works’), to the very specific (e.g. ‘Turpentine – Therapeutic use’). So unless you have a clear idea of what you’re looking for, some texts are likely to escape your notice. This problem stems from the generic diversity and disciplinary fluidity that characterises early modern science. So how do we classify texts that resist classification?
With the Visualizing English Print Project, I attempted to do this very thing. Extending those generic boundaries as far as I could, I created a corpus of just under 2000 scientific texts, drawn from the period 1482-1710.
In this post, I’m going to use the science corpus to examine texts from the first group to identify as a community of like-minded scientists: the Royal Society. What were the most common linguistic features of Royal Society prose?
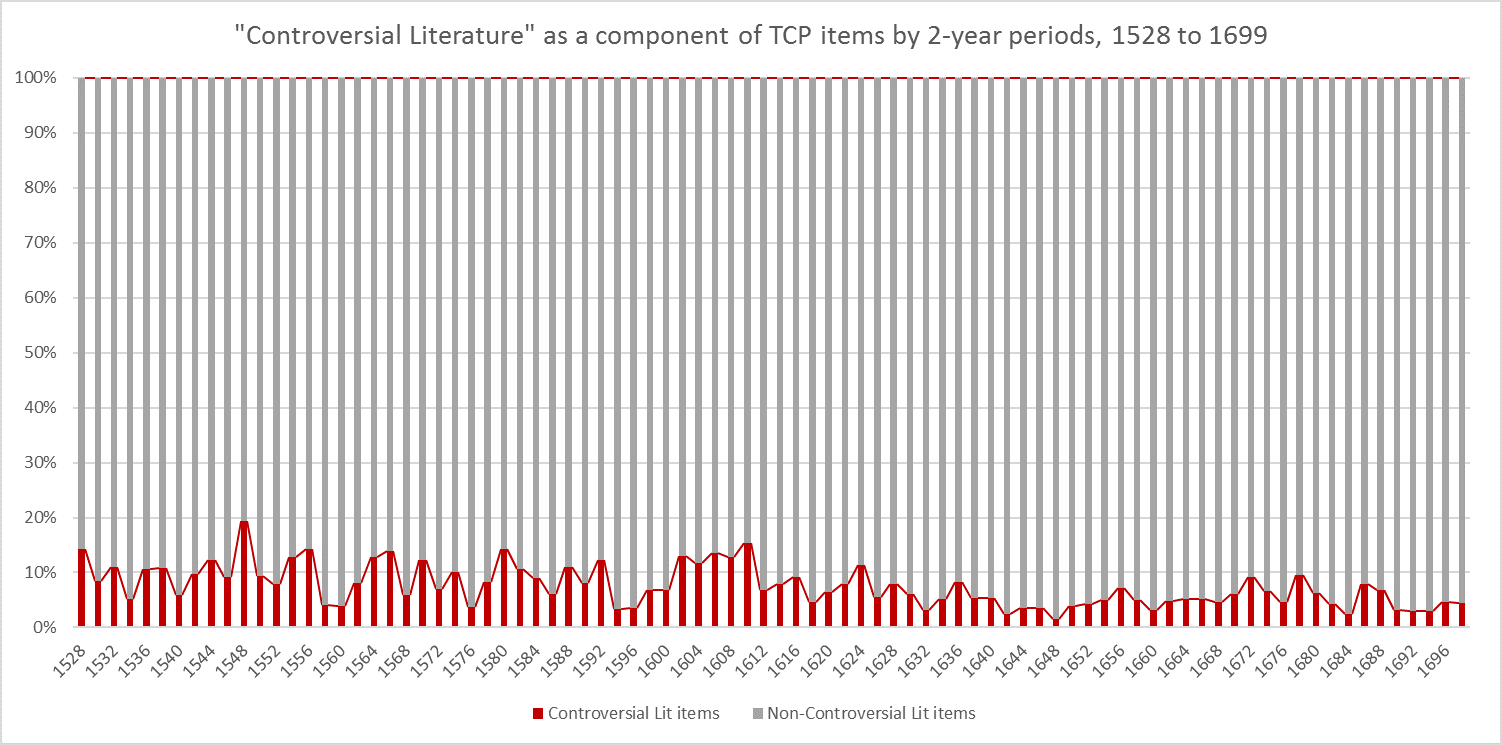
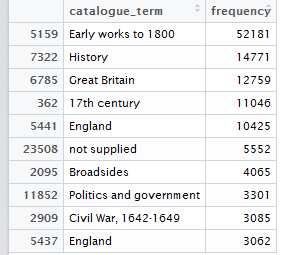
There are 233 Royal Society texts in the corpus, 11.8% of the whole (see Figure 1).

Figure 1 (left) Percentage of Royal Society Texts vs Rest of Science Corpus, 1482-1710. Figure 2 (right) Percentage of Royal Society Texts vs Rest of Science Corpus, 1660-1700.
Whether seen as a whole or in comparison to other texts from the period 1660 (when the Royal Society formed) to 1700 (Figure 2), Royal Society publications make up a small fraction of the total number of scientific texts. Fellows of the Royal Society wrote about subjects that spanned existing and emerging scientific fields. Yet these relatively small figures are partly explained by the scope of the corpus, which includes multiple disciplines, ranging from medicine to astrology.
The Language of the Royal Society
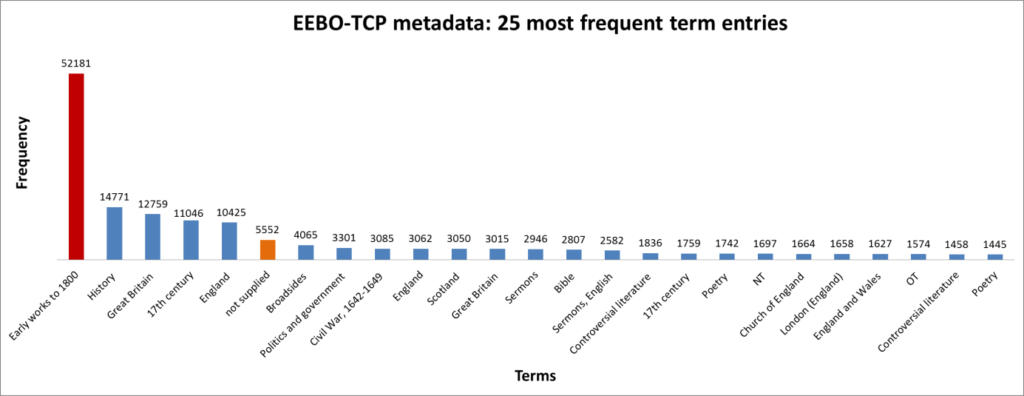
As well as promoting a new experimental method, key members of the Society (e.g. Robert Boyle, Thomas Sprat) were known for advocating a ‘plain’ style with which to recount experimental activities. On this basis, we might expect Royal Society texts to exhibit a certain coherence, when compared with non-society affiliated scientific texts. Figure 3 (below) shows the entirety of the science corpus (visualised using Principal Components Analysis), with Royal Society texts highlighted in red:
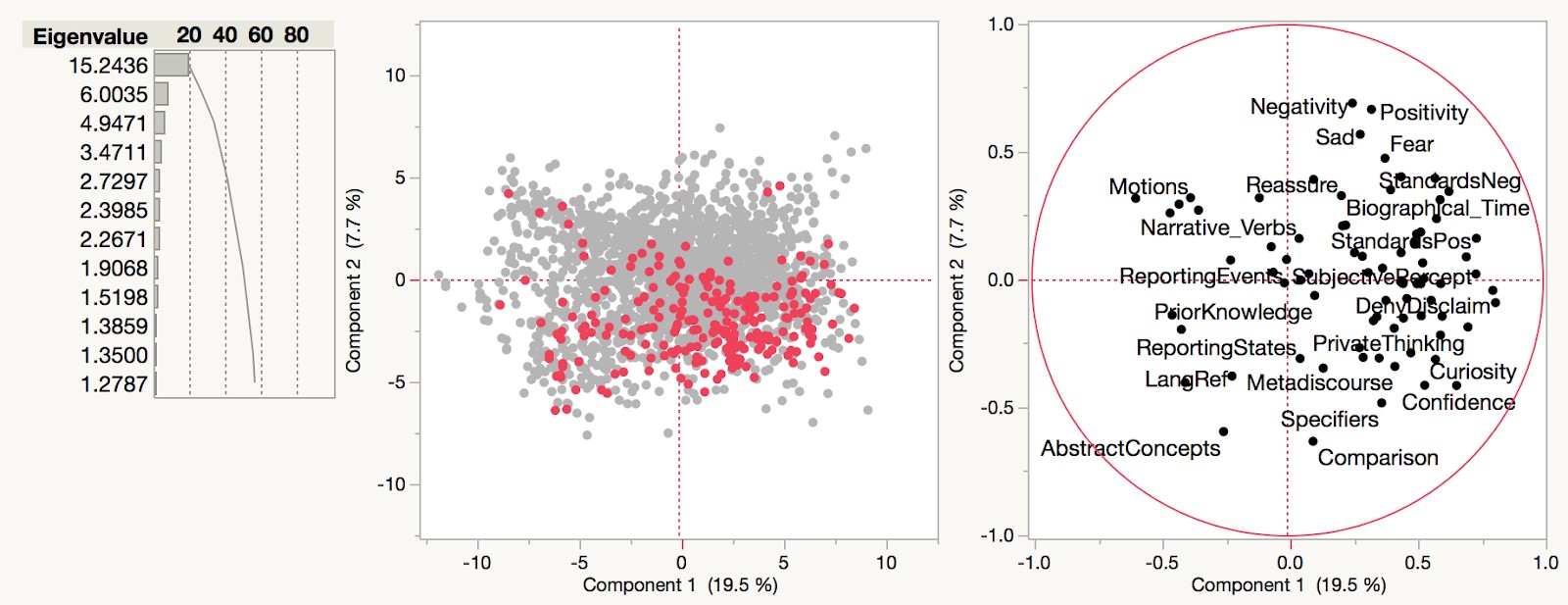
Fig. 3 PCA Scatterplot showing Science corpus, with RS texts highlighted.
Each text has been tagged using Docuscope software. Docuscope counts frequencies-per-text of the rhetorical categories shown on the loading plot (right). These categories contain words, phrases and punctuation. The dots in the lefthand scatterplot represent individual texts in the corpus. The scatterplot highlighting reveals that the highest density of Royal Society texts occurs in the lower right quadrant. From the categories in that quadrant we can tell that this kind of writing is broadly discursive. These categories include:
- ‘Comparison’, which tags comparative and superlative adjectives, such as ‘more than’ or ‘the largest’, as well as a variety of terms and phrases for difference;
- ‘Deny Disclaim’ (which tags terms such as ‘no’, ‘not’ and ‘none’); and
- ‘Private Thinking’, which captures words and expressions that deal with the processes of thought: ‘think’, ‘intellect’, ‘imagine’ etc.
But the graph also shows a distribution of Royal Society texts in the upper and lower left quadrants. The upper left quadrant has a high proportion of texts, such as medical recipe books. The lower left quadrant contains texts on mathematics and physics. Broadly speaking, discursive types of writing score high on Principal Component 1 (the x-axis), whilst procedural writing scores low. Perhaps unsurprisingly for a group with wide-ranging interests, Royal Society texts feature both procedural and discursive styles across Principal Component 1.
In order to get a closer look at the kinds of language used by members of the Royal Society, we can compare works by individual authors. Figure 4 shows the works of three figures: Margaret Cavendish, Duchess of Newcastle; Thomas Burnet; and the Society’s founding figure Robert Boyle.

Fig. 4 Table of texts under analysis by Boyle, Burnet and Cavendish, with publication date.
Margaret Cavendish’s philosophical outlook was at odds with that of the Royal Society. She was a vocal opponent of the experimental method and in her Observations upon Experimental Philosophy (1666), famously attacked new developments in microscopy, pioneered by Robert Hooke and Henry Power. In 1667 she became the first woman to attend a meeting of The Royal Society, during which she was shown a number of experiments. This demonstration did nothing to lessen her scepticism, or alter her commitment to rationalist principles. Burnet’s fame in the late seventeenth century mostly derived from his publication of The Sacred Theory of the Earth (1684), an account of the origins of the Earth after the flood (Genesis 6:9-9:17). His interactions with The Royal Society extended to correspondence with Isaac Newton in the winter of 1680-81. But the influence of The Sacred Theory was such that many Fellows of The Royal Society engaged with the book’s themes, including Edmund Halley and William Whiston.
Boyle, Cavendish and Burnet were selected because of their relative closeness within the lower right quadrant of the first scatterplot above (Fig.3). Each author’s texts can be classified as discursive prose (see Fig. 4). When compared against each other (Figure 5, below), the texts group by author, which means there may be stylistic differences at play, variations in subject matter, or both.
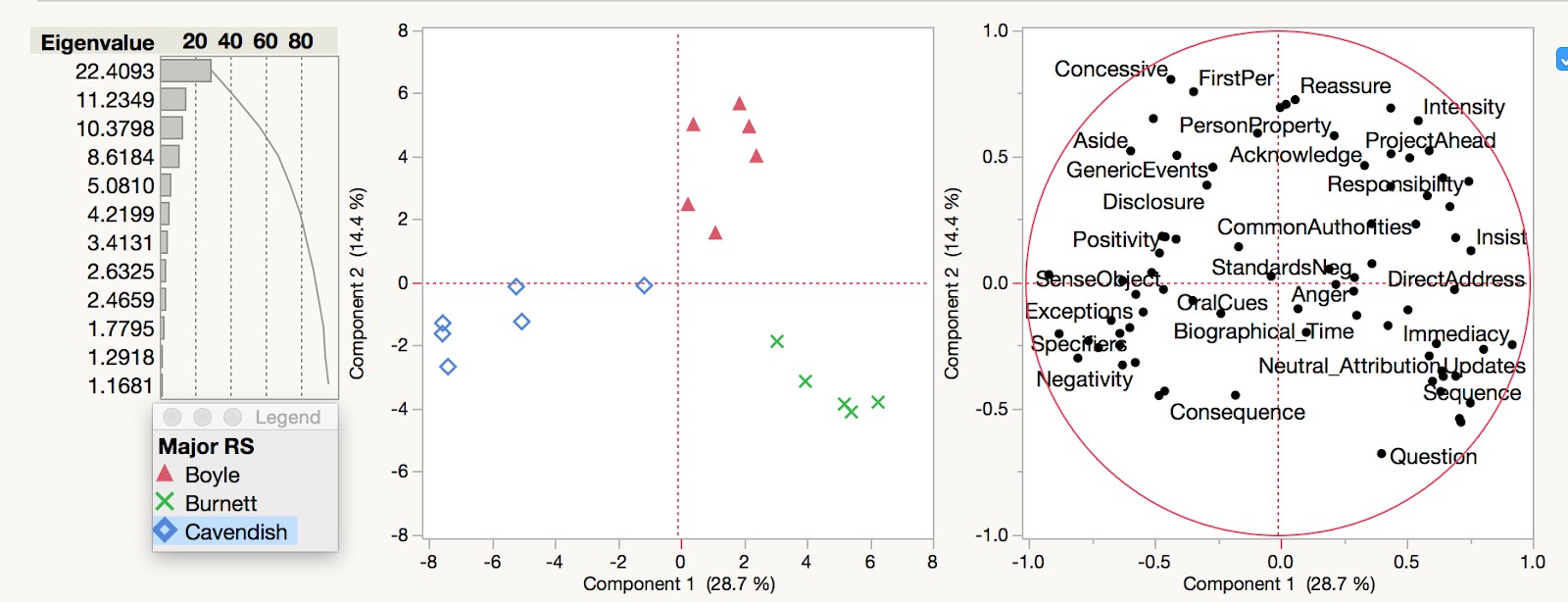
Fig. 5 PCA scatterplot comparing texts by Boyle, Burnet and Cavendish.
Boyle’s Language
The following graph (Figure 6) provides an indication of some of the linguistic variables that separate these texts into author groupings:

Fig. 6 Means of ‘Curiosity’, ‘Self Disclosure’ and ‘Intensity’ across works of Boyle, Burnet and Cavendish.
The graph measures the mean of individual linguistic categories, and shows the relative frequencies with which they are used by each author. So, Boyle’s texts use the language of ‘Curiosity’, ‘Intensity’ and ‘Self Disclosure’, more than those of Burnet and Cavendish.
To see what these linguistic features actually look like, here’s an example from Boyle’s Certain Physiological Essays (1669):
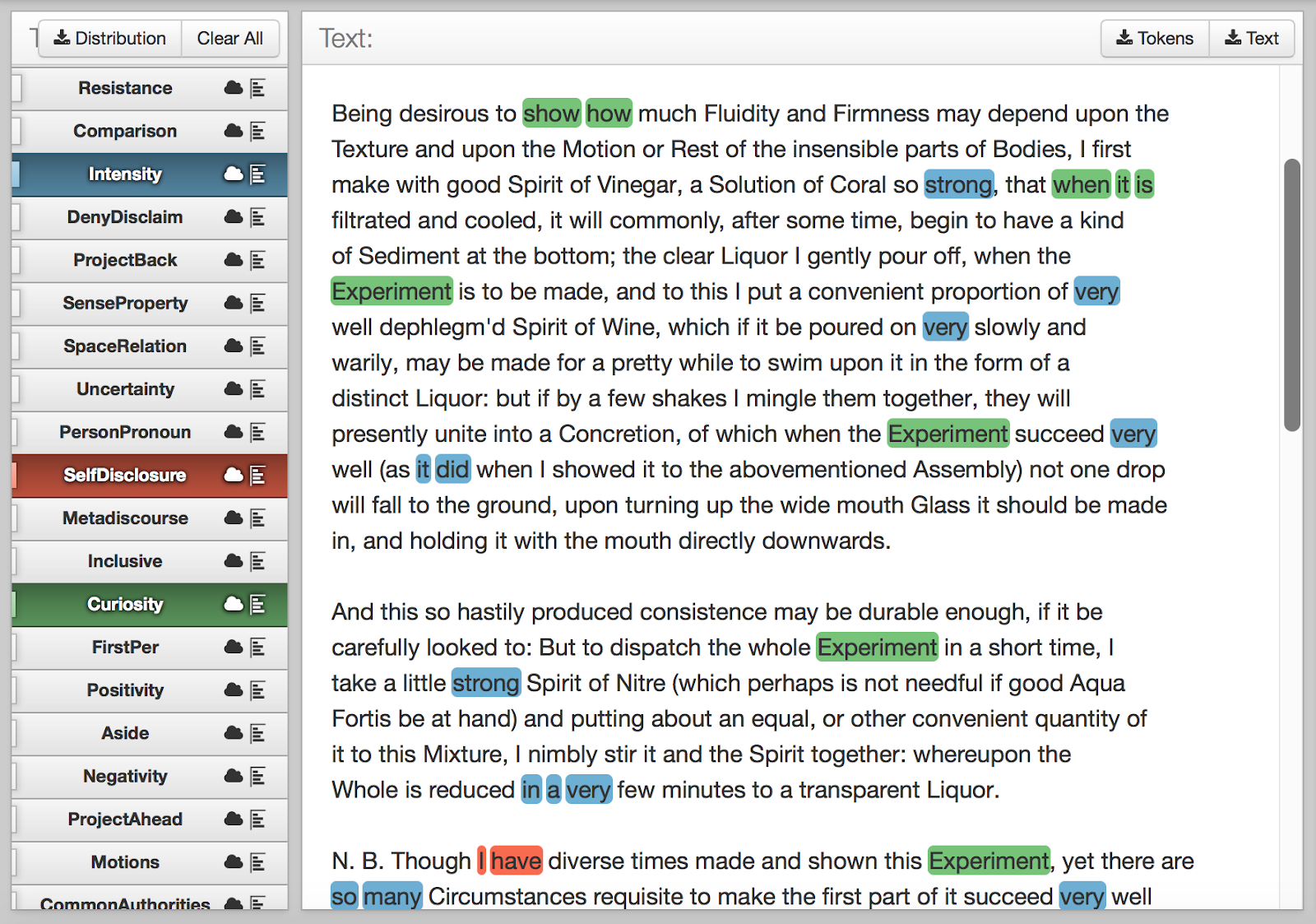
Extract from Boyle’s Certain Physiological Essays (1669), highlighting features of Intensity (blue), Self-disclosure (red) and Curiosity (green).
The linguistic category ‘Curiosity’ has captured Boyle’s methodological approach. Experimentation is at the heart of this method and Boyle refers to specific experiments throughout the essays. But ‘Curiosity’ also tags the language of experimental processes that precede discovery: ‘show how’, ‘when it is filtrated’. Boyle’s use of ‘Self Disclosure’ (‘I have diverse times’) assures the reader of his personal experience of conducting experiments. The frequent intensifiers (‘strong’, ‘very’, ‘so many’) create an impression of the thoroughness of descriptive detail, the kind of detail required if one were intending to replicate the experiment. Boyle professed that replication was a key aim of committing his experiments to print.
Burnet’s Language
This graph highlights some of the linguistic features that are most characteristic of Burnet – ‘Immediacy’, ‘Space Relation’ and ‘Intensity’:

Fig. 7 Means of ‘Immediacy, ‘Space Relation and ‘Intensity’ across works of Boyle, Burnet and Cavendish.
As you can see from Figure 7 (above), Boyle’s texts actually exhibit a little more Intensity than Burnet’s. I’ve included it here because Burnet uses intensifiers as a means of conveying the enthusiasm of his observations in a way that differs from Boyle.
Take this example from The Theory of the Earth (1697):

Extract from Burnet’s The Sacred Theory of the Earth, highlighting Space-Relation (green), Intensity (blue) and Immediacy (red).
Intensifiers, such as ‘greatest’, ‘most’ and ‘boundless’ contribute to this proto-romantic description of the mountains and seas. Given the geographic subject matter, it is unsurprising that Burnet’s use of ‘Space Relation’ eclipses that of Boyle and Cavendish: Docuscope has tagged phrases that indicate spaces (e.g. ‘the Earth’ ‘the tops of mountains’), but also an individual’s perception of these spaces (e.g. ‘behold’). ‘Immediacy’ adds to this immersive stylistic effect, which is achieved through a combination of geographical description and invitations to the reader to imagine him or herself within the landscape that Burnet describes: ‘let us now go’, ‘these things’, ‘these Mountains’.
Cavendish’s Language
With Cavendish, subject matter and style are different again. The following graph provides an impression of what separates her work from that of Boyle and Burnet:

Fig 8. Means of ‘Deny Disclaim, ‘Motions’, ‘Reason Forward’ and ‘Resistance’ across works of Boyle, Burnet and Cavendish.
The linguistic category ‘Motions’ captures words and phrases relating to various kinds of movement. The remaining categories (‘Deny Disclaim’, ‘Resistance’ and ‘Reason Forward’) register a pattern of argumentation in Cavendish’s texts.
We can see how these operate in this example from Observations upon Experimental Philosophy (1666), as Cavendish questions the epistemological value of the telescope and microscope:

Extract from Cavendish’s Observations upon Experimental Philosophy, highlighting Resistance (purple), Deny-Disclaim (blue), Reason-Forward (green) and Motions (red).
The ‘Motions’ that Cavendish describes (‘figurative motions’, ‘mix’, ‘sow’) are cited as examples of the essential uselessness of the experimental method: Microscopes may discern the motions of insects or reflected light in ‘Anatomical dust’, but they cannot provide answers to the larger questions, the causes of things. Cavendish’s rhetorical method supports her philosophical position: to reason, rather than to trust the senses. To this end, her pattern of reasoning is causal and tends to begin with refutations: ‘not found’, ‘no great benefit’, ‘neither’ and ‘nor’. Docuscope tags these as ‘Deny Disclaim’. Cavendish then moves onto expressions of contrast: ‘but are again dissolved’, ‘fallacies, rather than discoveries’ (tagged as ‘Resistance’). She ends with more assertive phrases that close the logical sequence of her argument: ‘so that a Gardener…’. These are tagged as ‘Reason Forward’.
The following example from the same text illustrates the circularity of this linguistic pattern:

Another extract from Observations upon Experimental Philosophy, highlighting Resistance (purple), Deny-Disclaim (blue) and Reason-Forward (green).
To conclude
This brief foray into the linguistic features of scientific prose has only scratched the surface of the differing stylistic choices that determine how a scientific author might write about a particular subject. Factors such as generic diversity mean that quantitative analysis of the whole science corpus can only give us a partial picture of how scientific language may have developed over time. This is before we take into account the incompleteness of the corpus, and of EEBO-TCP. But by looking at the relationship between specific texts and authors from a particular period, we can get a better impression of linguistic traits.
For example, Boyle, Burnet and Cavendish share an interest in the physical world. All of their texts discuss sensory objects and their motions. But their approaches to natural philosophy diverge. What’s interesting is how each author’s language use appears to support their respective methodological approaches to scientific inquiry. Where Boyle and Burnet foreground very different conceptions of experience as the way towards knowledge, Cavendish asserts that truth can only be reached through a process of rational thought, a process that can be detected in her rhetorical practice.
Header image: Dr Alan Hogarth presents at DRHA 2017 dataAche.