This post from 2015 outlines the challenge posed by non-standard spelling in early modern English with particular attention to Early English Books Online. It introduces two tools developed by others in order to assist searching and other language-based research: VARD and MorphAdorner.
The Linguistic DNA project relies on two very large linguistic data sources for evidence of semantic and conceptual change from c.1500 to c.1800—Early English Books Online Text Creation Partnership dataset (EEBO-TCP),and Gale Cengage’s Eighteenth Century Collections Online (ECCO).* The team has begun by digging into EEBO-TCP, assessing the data (and its dirtiness), and planning how to process it with all of its imperfections.
Early Modern English orthography is far from standardised, though standardisation increases considerably towards the end of the period in question. One of the goals of the EEBO-TCP project is to faithfully represent Early Modern English artefacts in digital form as both image scans and keyed texts. For Early Modernists, working with orthographic variation in such faithful transcriptions is no surprise. However, many users of EEBO-TCP, particularly public-facing users such as librarians, noted from the beginning that an average searcher might have difficulty with the number of false negatives returned by a search query—i.e. the number of instances of a word that the search interface fails to find due to their non-standard forms.
The orthographic standardisation that is part of a day’s work for Early Modernists is no small feat for computers. On the other hand, counting very large numbers of data points in very large data sets, and doing so very quickly, is exactly what computers are good at. Computers just need to be given clear and complete instructions on what to count (instructions provided by programmers with some help from Early Modernists).
ProQuest addressed the issue of spelling variation in their Chadwyck EEBO-TCP web interface with VosPos (Virtual Orthographic Standardisation and Part Of Speech). VosPos was developed at Northwestern University, based on research by Prof. Martin Mueller and the staff of the Academic Technologies group. Among other things, VosPos identifies a part of speech and lemma for each textual word, and matches each textual word to a standard spelling. Users searching EEBO-TCP for any given word using a standard spelling can thus retrieve all instances of non-standard spellings and standard or non-standard inflectional forms as well.
Querying EEBO-TCP for ‘Linguistic DNA’
Our project aims to analyse the lexis in the entire EEBO dataset in various ways, all of which depend on our ability to identify a word in all of its various spellings and inflections. While the VosPos web interface is extremely useful for online lexical searches, it’s not the tool for the task we’ve set ourselves. So, we began by sorting through a sample of EEBO-TCP XML files, cataloguing some of the known, recurring issues in both spelling and transcription in the dataset—not just the Early Modern substitutability of v for u, for example, but also EEBO-TCP transcription practices such as using the vertical line character (|) to represent line breaks within a word. We quickly came to two conclusions: First, we weren’t going to build a system for automatically standardising the variety of orthographic and transcription practices in the EEBO data. Because second, someone else had already built such a system. Two someones, in fact, and two systems: VARD and MorphAdorner.
VARD (VARiant Detector)
VARD aims to standardise spelling in order to facilitate additional annotation by other means (such as Part-of-Speech (POS) tagging or semantic tagging). It uses spell-checking technology and allows for manual or automatic replacement of non-standard spellings with standard ones. VARD 1 was built on a word bank of over 40,000 known spelling variants for Early Modern English words. VARD 2 adds additional features: a lexicon composed of words that occur at least 50 times in the British National Corpus, and a lexicon composed of the Spell Checking Oriented Word ListVARD 2 also includes a rule bank of known Early Modern English letter substitutions, and a phonetic matching system based on Soundex. VARD identifies non-standard spellings and then suggests a standard spelling via the following steps: identifying known variants from the word bank; identifying possible letter replacements from the rule bank; identifying phonetically similar words via the phonetic matching algorithm; and, finally, calculating a normalised Levenshtein distance for the smallest number of letters that can be changed for the textual word to become the standard spelling. VARD learns which method is most effective over time for a given text or set of texts, and additional parameters (such as weighting for recall and precision, respectively) can be manually adjusted. VARD has already been incorporated into the SAMUELS semantic tagger by Alistair Baron at Lancaster University alongside our own team members at Glasgow University, Marc Alexander and Fraser Dallachy.
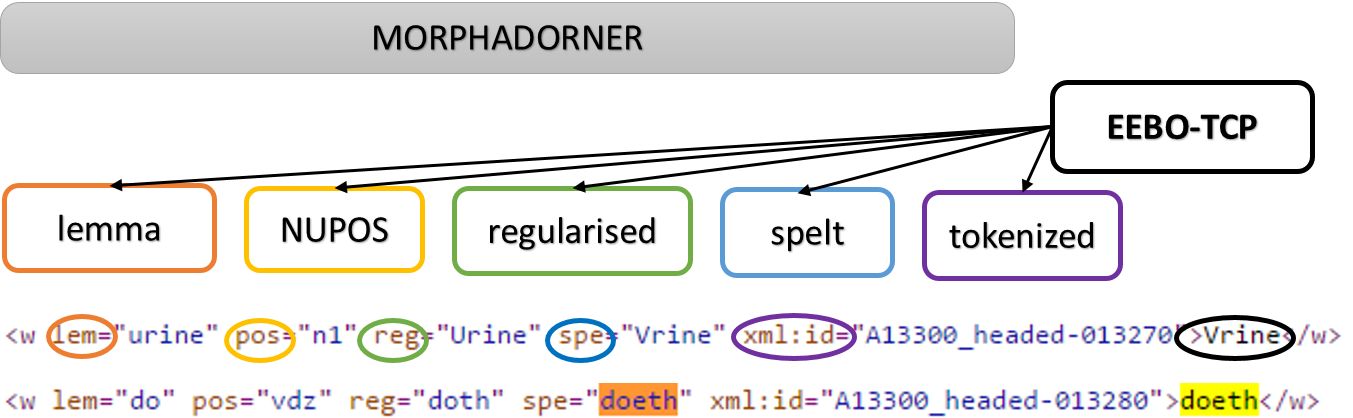
MorphAdorner
MorphAdorner, like VosPos, was developed at Northwestern University by a team including Martin Mueller and Philip Burns. MorphAdorner 2.0 was designed to provide light but significant annotation for EEBO-TCP in particular, expanded to an array of other digital texts, towards what Mueller calls a ‘book of English’, a highly searchable corpus covering the full history of the language, from which a variety of information could be extracted efficiently. To that end, MorphAdorner includes two tools for POS-tagging (a trigram tagger and a rule-based tagger), and incorporates POS data in its spelling standardisation. Word banks for spelling standardisation are drawn from the OED and Webster’s data, as well as from EEBO-TCP training data, adding up to several hundred thousand variant forms. Those word banks are supplemented by a rule bank in identifying appropriate alternates. MorphAdorner recommends a standard spelling via the following steps: applying all rules from the rule bank to determine if any result in a standard spelling or a spelling that matches a known variant in the rule bank; calculating edit distance for the resulting spellings for the smallest number of letters that can be changed to turn the textual word into the known variant or standard spelling; calculating a weighted string similarity between the original word and the known variants or standards, based on letter pair similarity, phonetic distance, and edit distance; identifying the POS of the original word and limiting the possible variants by POS; selecting the found spelling with the highest similarity.
Some of the transcription issues in the EEBO-TCP data are solved within the MorphAdorner pipeline before the spelling standardisation process begins, partly by using Abbot, another system designed at Northwestern University (by Mueller and Burns), which converts dissimilar XML files into a common form. Abbot can therefore be used to automatically convert some of the EEBO-TCP XML transcription norms into a form that is more easily readable by MorphAdorner. Logically, this clean-up should improve things for VARD too.
So, what’s the best tool for our job?
There was considerable discussion of both VARD and MorphAdorner at last month’s Early Modern Digital Agendas institute at the Folger Institute in Washington, DC. On Twitter, @EMDigital reported that each was built with its own set of assumptions; that Folger’s Early Modern Manuscripts Online is now considering which one to use; and that the Visualising English Print project used VARD for standardisation but may switch to MorphAdorner in the future. Each tool has already been used in a variety of ways, some quite unexpected: VARD has been used to orthographically standardise classical Portuguese, and MorphAdorner has been used to standardise variation in contemporary medical vocabulary.
What will work best for us? Given the absence of documented comparisons for the two tools, we’ve realised we need to investigate what we can do with each.
The team is now working through the following stages:
- Pre-process a sample of EEBO-TCP transcriptions so that words are more readily identifiable for further processing. (This should strike out those vertical lines.)
- Take the pre-processed sample and process it using VARD and MorphAdorner, respectively. This will require optimising parameters in VARD (f-score balances and confidence threshold).
- Assess the resulting two annotated samples (the first ‘VARDed’ and the second ‘MorphAdorned’) in order to identify the strengths of each tool, and what benefits each might provide for the project.
We anticipate presenting the results of this process at the project’s methodological workshop at the University of Sussex in September, and will post updates on the blog as well.
Further Reading:
Basu, Anupam. 2014. Morphadorner v2.0: From access to analysis. Spense Review 44.1.8. http://www.english.cam.ac.uk/spenseronline/review/volume-44/441/digital-projects/morphadorner-v20-from-access-to-analysis. Accessed July, 2015.
Gadd, Ian. 2009. The Use and Misuse of Early English Books Online. Literature Compass 6 (3). 680-92.
Humanities Digital Workshop at Washington University in St. Louis. [nd]. Early Modern Print: Text Mining Early Printed English. http://earlyprint.wustl.edu/. Accessed July, 2015.
Mueller, Martin. 2015. Scalable Reading. [Blog]. https://scalablereading.northwestern.edu/. Accessed July, 2015.
* Initially, we planned to include the full body of Gale Cengage’s Eighteenth Century Collections Online (ECCO) in our analysis. A later post explains why most of ECCO was not reliable for our purposes. Our interface incorporates the small portion of ECCO that has been transcribed through the Text Creation Partnership (ECCO-TCP).