In 2015, we compared two tools developed to address spelling variation in early modern English: VARD and MorphAdorner. This post documents some of that work, outlining how the design and intent of the two tools affects their impact.
The Sheffield RAs are hard at work on our audit of Early English Books Online, figuring out how best to clean up the TCP data for Linguistic DNA’s research goals. In the last post, Seth documented our intention to try out 2 of the tools that have evolved as a method of analysing the data: VARD and MorphAdorner. What we wrote there was based on our reading. So what have we found in practice?
VARD: Spell-checking early modern English
Give VARD an early modern text and it will do two things: spell-check and modernise.
When a word matches a word form in current English, VARD will move on to the next word.
Standard historic verb forms such as “leaveth” and “believest” will be modernised (“leaves”, “believe”). Some archaisms survive this process, e.g. “hath”. The second person singular pronoun “thou” is also allowed to stand, though this can result in some ungrammatical combinations; e.g. a VARD-ed text yielding “thou believe”.
For non-standard or unrecognised spellings, VARD identifies and calculates the probabilities of a range of possible solutions. It implements the ‘best’ change automatically (at the user’s instigation) only if its confidence exceeds the chosen parameters. For our samples, we have found that setting the F-Score at 2 (a slight increase in recall) achieves optimal results with the default threshold for auto-normalisation (50%). For the 1596 pamphlet, The nature of Kauhi or Coffe, and the Berry of which it is made, Described by an Arabian Phisitian, this setting automatically resolves “Coffee” (56.89% confidence) and “Physician” (76%).
VARD’s interventions are not always so effective. Continuing with the coffee text (EEBO-TCP A37215) we observe that VARD also amends the Arabic month name Ab to Obe, a noun referring to villages in ancient Laconia, (50.12%). This weakness reflects the fact that VARD operates with lexicons from a specified language (in this case modern English) and measures the appropriateness of solutions only within that language.1 Another problematic amendment in the sample is the substitution of “Room” for “Rewme” (actually a variant of the noun ‘rheum’).
In the four texts we have sampled, VARD introduces some important corrections. But it also introduces errors, resolving “Flix” (Flux) as “Flex”, “Pylate” (Pilate) to “Pilot”, and “othe” (oath) to “other”. Each such intervention creates one false positive and one false negative when the texts as a whole are counted and indexed.
The false positive/negative dilemma also presents when an early modern word form matches the standard form of a different word in modern English. The verbs “do” and “be” appear frequently in EEBO-TCP with a superfluous terminal “e”. To the uninitiated, an index of VARDed EEBO-TCP might suggest heightened interest in deer-hunting and honey-production in the latter quarter of the sixteenth century.2
MorphAdorner
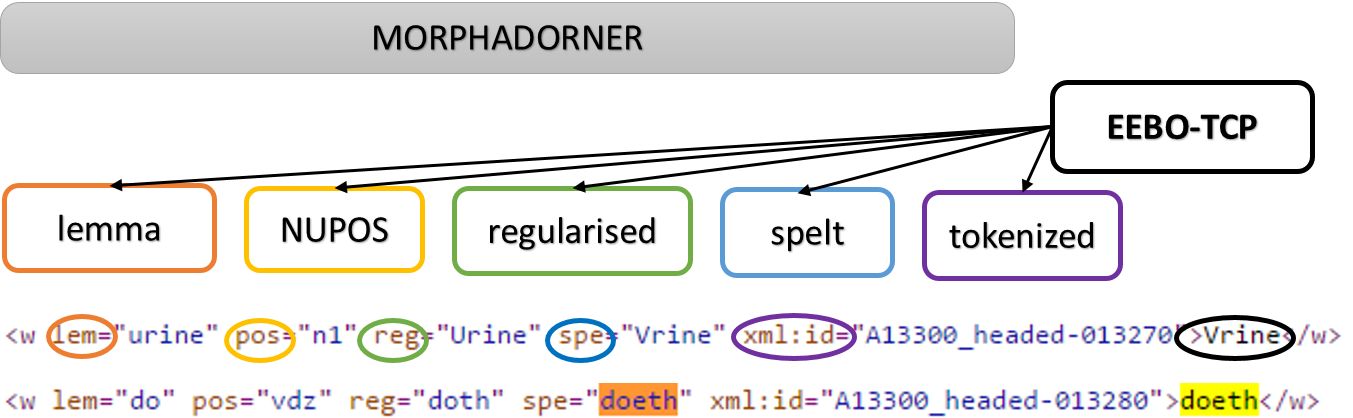
MorphAdorner is set up for more extensive linguistic processing than VARD. From the basic input (the EEBO-TCP form), it tags or adorns that input with a minimum of five outputs.
- A unique xml:id
- An ‘actual spelling’ (spe)3
- A regularised spelling (reg)
- A part-of-speech tag (using the NUPOS tag set)
- A lemma
Initially, MorphAdorner itemises the XML input creating a reference system that allows changes to be mapped and revisited. This is reflected in the xml:id.
The pros and cons of such output and the actual performance of MorphAdorner under observation is better understood when illustrated with some examples.

Figure 1
As shown in Figure 1, in a medical text (A13300) “Vrine” is regularised to “Urine”, identified as a singular noun (n1) and indexed by the lemma “urine”. The verbal form “doeth” is regularised as “doth” and lemmatised as “do”. Its part of speech tag (vdz) designates “3rd singular present, ‘do'”.
Where the word form has been broken up by the TCP processing—whether because of a line-break in the original text or some other markup reflecting the format of the printed page—MorphAdorner is able to calculate and tokenise the whole word. So at the start of the coffee pamphlet, the first letter is printed with a decorated initial (“B”); to interpret it as part of the word form “Bun” (the name of the coffee plant in Arabic) means joining these portions together as ‘parts’ of a single word that then becomes a candidate for regularisation and lemmatisation (see Figure 2).

Figure 2
(MorphAdorner’s solution here is not ideal because it does not recognise the word as ‘foreign’. The lack of any preceding determinative means the word is taken as a proper noun which minimises the disruption of this false positive.)
It is noteworthy that MorphAdorner resolves “it selfe” into “itselfe” and thus regularised and lemmatised “itself”. This is not something VARD can achieve. However, the problem of collocations that were written in separate parts but have become compounds in modern English is more profound. Both MorphAdorner and VARD process “straighte way” (A13300) as “straight way”, “anye thinge” (A04975) as “any thing”, and leave “in soemuch” (A13300) untouched; counting only these single instances results in half-a-dozen false positives and three false negatives.
There are other items that cause problems but the most striking outcome of the comparison so far is a set of failures in the regularisation process. Three examples are given below:
- “sight” is regularised to “sighed” (8 occurrences in A13300)
![]()
- “hot” is regularised to “hight” (3 occurrences in A37215; 50 occurrences in A13300)
![]()
- “an” is regularised to “and” (2 occurrences in A37215; 276 occurrences in A13300)
![]()
In each case the original spelling is an ordinary English word (something VARD would leave untouched) being used normally and the token is lemmatized correctly, but the regularisation entry represents an entirely separate English word. These problems came up in the small sections we sampled. That they reflect a problem with MorphAdorner rather than our application of it is evident from a search for “hot” and “hight” using the “regularized spellings” option via the Early Modern Print interface.
In effect, this indicates that MorphAdorner’s lemmatization may be significantly more reliable than the regularisation. It also means we may need to continue experimenting with VARD and MorphAdorner, and find automated ways—using comparisons—to look for other similarly ‘bugged’ terms.
Notes
1 It is possible to instruct VARD that a particular word or passage is from another language, and even to have it VARDed in that language (where a wordlist is available) but this requires human intervention at a close level.
2 A CQPweb query showed “doe” exceeding 6 instances per million words (ipmw) in 1575–1599, with “bee” at 88.21 ipmw in 1586—the latter disproportionately influenced by the 265 instances in Thomas Wilcox’s Right godly and learned exposition, vpon the whole booke of Psalms (≈ 704 ipmw).
3 In fact this already incorporates some replacement rules, so that “vrine” may be given the spe entry “urine” (cf. xml:id A13300_headed-018250); less productively, the rules also change “iuices” to “ivices” (A13300_headed-036790). Logically creating such permutations increases the possibility that MorphAdorner will detect a direct match in its next step. It may be that the “spe” field is an ‘actual or alternative’ spelling field.
Texts sampled:
The extracts analysed comprised between 200 and 400 tokens from each of the following EEBO-TCP documents:
- A04975: The pleasaunt playne and pythye pathewaye leadynge to a vertues and honest lyfe no lesse profytable, then delectable. V.L. [Valentine Leigh] London, ?1552. (STC 15113.5)
- A13300: A rich store-house or treasury for the diseased Wherein, are many approued medicines for diuers and sundry diseases, which haue been long hidden, and not come to light before this time. Now set foorth for the great benefit and comfort of the poorer sort of people that are not of abilitie to go to the physitions. A.T. London, 1596. (STC 23606)
- A14136: The obedie[n]ce of a Christen man and how Christe[n] rulers ought to governe…., William Tyndale, [Antwerp] 1528. (STC 24446)
- A37215: The nature of the drink kauhi, or coffe, and the berry of which it is made described by an Arabian phisitian. English & Arabic. [Anṭākī, Dāʼūd ibn ʻUmar, d. 1599.] Oxford, 1659. (Wing D374)

It is true that MorphAdorner does better on lemmatization than regularization, largely because lemmatization and POS tagging have gone through several rounds of review while the review of regularization has lagged behind. But that is changing. In the Shakespeare His Contemporaries project the regularized spellings of some ten million word tokens have been reviewed. Richard Proudfoot has been helpful in submitting half a dozen texts to a thorough review, with his suggestions cascading through thousands of tokens. More about this at https://scalablereading.northwestern.edu/2015/07/25/hannah-kate-lydia-and-shakespeare-his-contemporaries-shc/ and https://scalablereading.northwestern.edu/2015/06/07/shakespeare-his-contemporaries-shc-released/
I expect that before the end of 2015 we will have a MorphAdorned corpus of at least the Phase I texts that will include many improvements, including particularly significant improvements in the accuracy of regularized forms.