
When the Linguistic DNA project was first conceived, we aimed to incorporate more than 200 000 items from Eighteenth Century Collections Online (ECCO). Comparing findings for one portion of ECCO that has been digitised in different ways, this 2016 blogpost details why that ambition proved impractical. The public database uses ECCO-TCP as its main eighteenth-century source.
LDNA acquired the data from Gale Cengage’s Eighteenth Century Collections Online in April, with the goal of using it to explore the structure and evolution of concepts in the period from 1700 to 1800. As with EEBO last summer, the project Research Associates (Seth, Fraser and Iona) set out to audit this new dataset and assess the challenges it might present.
About ECCO-OCR
As with many other historical text collections, Gale integrate images of the documents with a machine-generated digitised version of the text. The latter version is produced using complex algorithms to identify individual letters in the image of the printed pages, using a technique known as Optical Character Recognition (OCR). The OCR technique has advantages: For each item identified, both transliteration and position on the page are recorded. The search results returned by Gale’s ECCO portal combine this information, highlighting the item on the page-image, allowing quick verification that this is a sound transliteration, and giving the seeker ready access to the context.
That said, regular ECCO users will know that the transliteration is sometimes imperfect. And though searches may find many items that a pre-digitisation scholar might have struggled to discover, the errors are such that not every instance of a search term in the printed text will be recovered by the search.¹ For this reason, those using ECCO need to be cautious about drawing inference from absence. Is “suddenly” much rarer than “immediately”, or simply harder to OCR correctly because of features like the long “s”?
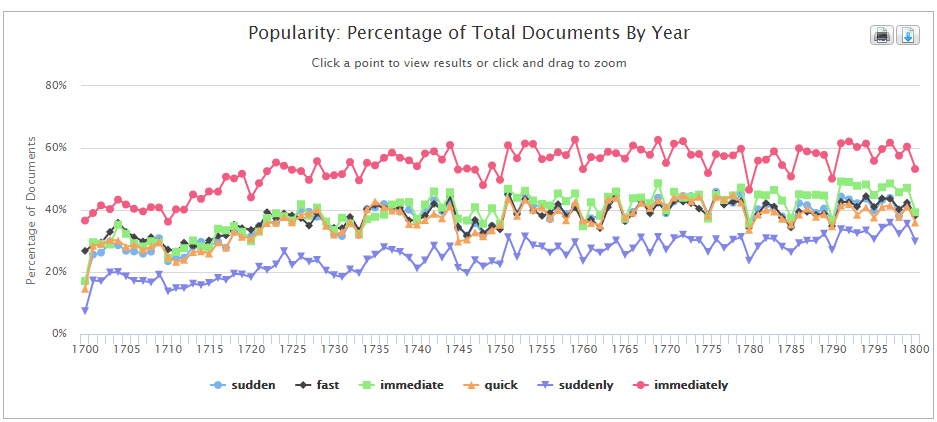
This graph generated using Gale Cengage’s Artemis interface plots the percentage of monographs containing search terms by year across the ECCO population using the OCR’d text, visualising the apparent “popularity” of forms including “suddenly” (purple) and “immediately” (red).
For a detailed account of the considerations for a researcher working on eighteenth-century materials, see Patrick Spedding’s article, “The New Machine“.
OCR and historical documents
The challenges of OCR are well documented. Cutting-edge software can be extremely effective at processing modern documents. Historical documents present more challenges, as discussed by the archivists responsible for large newspaper collections in Britain, the Netherlands, and Australia. The peculiarities of eighteenth century newspapers are perhaps not as extreme as the enterprising typesetting seen in the Thomason Tracts (see Amy Jackson’s report). But newsprint customarily employed low quality paper and inks, and was produced at speed. Thus many of the most extensive collections of historical documents rely on data that can never be optimised for OCR. Moreover, the memory requirements of digitising large text collections as images were formerly such that many online collections—including ECCO—are made up of low quality black and white images, readable for humans but a challenge for the machines.
The Mellon-funded eMOP project, based at Texas A&M University, was dedicated to the goal of improving ECCO’s OCR but found it an uphill task. A separate project led by the University of Texas is working on OCR for Primeros Libros, a collection of works in Spanish, Latin and Nahuatl printed in the Americas pre-1601. In that work, they have sought to engage directly with the typefaces and employ highly optimised word recognition and multiple language models within the OCR processes. Such approaches lie outside the scope of LDNA.
So what are we doing?
Comparing OCR and TCP
Our existing process has been designed to work with the Text Creation Partnership’s transcriptions of earlier printed works (i.e. EEBO-TCP) as documented in previous posts. We employ MorphAdorner to regularise spellings and lemmatise each text, and then run co-occurrence queries across relatively large windows (currently up to 100 words to both left and right of a node word). As part of the query, we calculate the Pointwise Mutual Information (a statistical measure, but not an assessment of significance) for each pair of words within the corpus.
The body of work underwritten by the Text Creation Partnership extends beyond EEBO to take in a selection of works from the Eighteenth Century, in effect a subset of ECCO, known as ECCO-TCP. Happily for LDNA, this subset can be utilised as a parallel corpus. Extracting the same set of 2169 documents from Gale’s OCR data, we can then run that through our processes and inspect differences in the output. We can use this to answer questions including “To what extent is MorphAdorner able to fix OCR errors?”, “What is the relationship between character errors and word errors?”, and “What is the impact of word errors on the identification of coocurrence patterns?”
At a fundamental level, we need to know whether the ECCO OCR data is of sufficient quality to be part of our processor design phase.
Observations so far
To begin with, we made a mistake: our TCP pre-processing disregards punctuation, so that for a window of 1 to left and right, (“W2” in LDNA terms), punctuation is not counted as a co-occurrence. In setting up our exercise, we did not extract the punctuation from the OCR dataset. For the W2 PMIs under scrutiny, this has a substantial effect on the PMI for word-pairs where one often appears next to punctuation. In the TCP dataset, looking at MorphAdorner’s regularised output, the word pair “but” and “translated” co-occur 13 times in W2; the parallel OCR version counts only 5 co-occurrences, a ca. 62% ‘loss’. Overall, less instances of “translated” are found in the OCR dataset (fTCP 2523, fOCR 1741), and this gap could theoretically account for the co-occurrence loss. More probable though is that in some cases a punctuation character intervenes between the word pair “translated, but” and so some of the ‘loss’ is actually because the processor has counted these as co-occurrences of “,” and “but”.
The punctuation issue distorts co-occurrence patterns. It does not affect the baseline frequencies for any word form in the two datasets. The chart below offers a window on these baseline frequencies, taking as a starting point word forms that begin with the stem “transl-“, including lower and upper case variations. Taking all qualifying words together, there are 8356 occurrences in the TCP and 5930 in the OCR. The first row of the chart shows that OCR figure as a percentage of the TCP. Subsequent lines show how the percentages vary for different word forms, so that e.g. “transl” exists only in the TCP (OCR: 0%), while “TRANSLATIONS” occurs an equal number of times in OCR and TCP (OCR: 100%).

Chart comparing frequency of words from the stem “transl-” in the sample. The pink bar shows OCR frequency as % of total ECCO-TCP frequency for form. Total TCP tokens shown at far right of bars.
Overall, for the stem “transl-“, the OCR finds only 71% of the total instances known to the TCP. The OCR is especially unsuccessful at recognising “Translator” (52%, missing 143 instances), whereas most transcribed occurrences of “translator’s” seem to be identified within the OCR version (91%, missing 2 instances).
[As this chart only shows words that occur at least once in the regularised TCP, the form “translatcd” which occurs 41 times in the OCR text (reading “c” for “e”) is not shown. Many of the OCR errors appear to mistake “s” for “f”, a well-known OCR error of the kind that might be resolved using Underwood and Auvil’s work.]Even taking the shortcomings of our experiment into account, the current intuition is that there are too many problems within the OCR dataset to use it during the design phase. We will instead seek to work with eighteenth century data from other sources (including ECCO-TCP). This leaves open the possibility of returning to ECCO-OCR later in the project, to evaluate the accuracy of the information extraction techniques when working with a messier dataset.
Those with eighteenth century data in a suitable digitised form are welcome to get in touch!
[1] Another frustrating outcome is the false positive, when one or more rogue characters add up to a different word.
