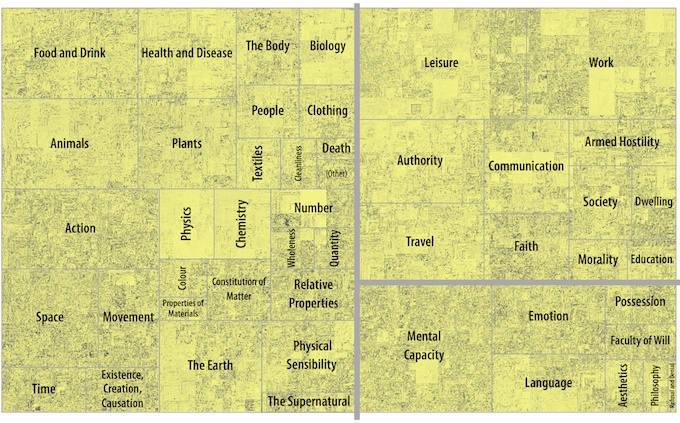
Visualising modern English by concept (based on data from the Historical Thesaurus of English). Image by Marc Alexander. [http://historicalthesaurus.arts.gla.ac.uk/visualisations/]
The Linguistic DNA of Modern Western Thought used digital methods and resources to analyse more than 5 million pages of printed texts. This data represents works printed in English, or in England, Ireland, Scotland, and Wales from 1473 to 1800.
For the early part of our period, we worked with the ca. 58,000 texts digitised as part of the Early English Books Online Text Creation Partnership collaboration (EEBO-TCP). From 1700, our major source is Gale Cengage’s Eighteenth Century Collections Online (ECCO). These resources allow an unprecedented level of comprehensiveness in the analysis of language, semantics, and conceptual history in the Early Modern period. The project applied computational tools to these resources to analyse details of Early Modern English vocabulary and semantics, including instances of social and cultural keywords and their shifting frequencies, meanings, and uses in various contexts over time. The result was a rigorous, systematic, and scientific account of Early Modern conceptual history via its linguistic data.
In addition, the project also incorporated the recently completed Historical Thesaurus of English. The thesaurus serves as a taxonomy of language history as it is captured in the Oxford English Dictionary; it organises the 793,000 word senses in the OED and other sources into semantic categories, which can nest inside wider categories in a taxonomy up to twelve layers tall. As such, the architecture and database of the thesaurus are key to identifying concepts in the texts explored in this project.
Using the resources described above, it is possible to discern trends, relationships, and anomalies across an enormous amount of linguistic data to identify the often surprising complexities, continuities, and discontinuities inherent to linguistic and conceptual change.